

从政策推动到研究产出——浅析医院主导人工智能研究的技术性挑战
2023-05-10 13:35
来源:中国网·中国发展门户网




中国网/中国发展门户网讯 近年来,人工智能(AI)正在加速融入医疗健康相关研究中。医院是我国医疗健康领域重要的人工智能研究基地与产出基地。目前,对医院主导人工智能研究现状调查尚不充分。部分关于医院人工智能的研究仅强调了外部资源局限和一些常见的伦理问题。一些定量研究虽关注了医疗健康人工智能研究状况,并通过论文数量得出发展良好的结论,但其分析层面较为宏观,未能指出发展中不均衡、不充分的部分。本文对医院主导人工智能研究的现况进行研究,分析医院主导人工智能研究需要面对和跨越的技术性难题,并针对性地提出管理建议。
政策推动医院开展人工智能研究
我国高度重视人工智能在医学中的研发与应用,将其作为新一轮科技革命和医疗健康产业变革的核心驱动力,并力图在新一轮科技竞争中抢占主导权。2017年,国务院印发《新一代人工智能发展规划》(国发〔2017〕35号)提出,要发展便捷高效的智能医疗服务,推广应用人工智能治疗新模式新手段,建立快速精准的智能医疗体系,探索智慧医院建设。2021年,《国务院办公厅关于推动公立医院高质量发展的意见》(国办发〔2021〕18号)明确,要推动手术机器人等智能医疗设备和智能辅助诊疗系统的研发与应用。2022年,科学技术部等六部门印发《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》(国科发规〔2022〕199号),进一步指出要积极探索医疗影像智能辅助诊断、临床诊疗辅助决策支持、医用机器人、互联网医院、智能医疗设备管理、智慧医院、智能公共卫生服务等场景。同年,国家卫生健康委员会与各省份签订的《共建高质量发展试点医院合作协议》中明确,要聚焦数字赋能,加强大数据、人工智能等跨行业新技术应用,建设医疗、服务、管理“三位一体”的智慧医院。“十四五”期末,试点医院形成中国智慧医院样板;“十五五”期末,面向世界提供智慧医院建设中国解决方案。
医院采用人工智能技术开展研究,有机会产出引领性、颠覆性的科技进步。传统上,医院主导的研究主要使用经典的数理统计来区别有效信息(信号)与无效信息(噪声),其技术核心是包括线性回归、Logistic回归、决策树等在内的一系列统计分析方法,纳入的数据大多为结构化的定量数据。采集和整理相关数据需要耗费大量的人力物力和时间。与这些统计方法相比,深度神经网络、机器学习的人工智能研究范式可明显扩展纳入研究的数据模态,增加数据量,并加速信息采集过程。与此同时,医院是医疗健康数据的重要生产基地;医院研究者更加贴近患者,更容易提炼出具有重大科学意义的医学问题及技术需求。这为医院主导人工智能研究提供了重要优势。当前,我国医院已在人工智能研究方向发力,在数据挖掘、图像识别、自然语言分析及机器人辅助等 4 项通用任务框架中,解决疾病诊断、治疗、健康管理和医院管理等方面的挑战。人工智能技术和医院的数据生产将共同赋能医院研究者,不断完善临床诊疗技术、构建智能医护模式、优化健康管理体系,产出传统研究方法尚无法解决的科学问题,从而孵化出满足国家战略需求和人民健康需要的重大科技进步。
人工智能临床应用研究已成为国际医学研究的重点方向和竞争热点。当前,美国、中国、英国是在医疗健康人工智能研究中贡献论文最多的国家 。2020年,美国国立卫生研究院(NIH)启动了一项总金额高达 1.3 亿美元的“通往人工智能之桥”(Bridge2AI)的资助计划,旨在资助生物医药等相关领域开展人工智能研究。国际一流医院也在努力布局人工智能的研发与应用。2022年,美国《新闻周刊》(Newsweek)和德国 Statista 调查公司发布了“世界智能化程度最高的 300家医院”榜单。该榜单中的智能化程度以“人工智能”“数字化影像”“机器人”等维度进行评估;排名前 10位的医院中,有5家医院被特别地标注了以“人工智能”为代表性领域。
医院人工智能研究数量及质量分析
样本医院
2021年,国家卫生健康委员会面向全国,选定了北京协和医院、北京大学第三医院、四川大学华西医院、香港大学深圳医院等 14家公立医院,作为国家公立医院高质量发展试点医院。这 14家医院感受到的政策推动更强,因而具有典型性。同时,部分样本医院具备较强的科学技术研究能力,而部分医院在科研方面能力较弱;通过对它们主导的人工智能研究发展现状进行调查,有助于了解我国医院主导人工智能研究的相关情况,具有一定程度的代表性。
研究方法
本文采用定量研究方法,对发表论文和申请专利 2个维度开展了研究。
发表论文方面,研究者对样本医院发表人工智能相关论文进行了统计。具体地,①从维普期刊平台和 PubMed数据库分别检索了这 14家医院以中文和英文发表在期刊上的论文,取回论文标题、作者、摘要、关键词、作者单位等信息。②采用关键词法在前述论文中识别人工智能相关论文。如果论文的标题、摘要、关键词中提及了“人工智能(artificial intelligence)”“机器学习(machine learning,ML)”“神经网络(neural network)”“支持向量机(support vector machine,SVM)”“卷积神经网络(convolutional neural network,CNN)”“残差网络(residual network)”等人工智能的标志性中文或英文关键词,则将其标记为人工智能相关论文。纳入研究的论文发表时间为 2018年—2022年;其中,因受新冠肺炎疫情影响较大,2020年暂不纳入调查。③对论文的数量、发表语言、研究层次等维度进行了统计和分析。
专利申请方面,研究者从国家知识产权局网站“专利检索及分析”系统检索了相同时间段内获批的、包含“人工智能”关键词的相关发明、实用新型专利项目,并对其数量进行统计。
发表论文分析
论文数量。样本医院在 2018年—2019年、2021年—2022年共发表中文和英文论文 13.34万篇;其中,人工智能相关研究论文 3 002篇,占比较低,仅为 2.25%。样本医院参与人工智能研究论文数从 2018年的222篇逐年增长至 2022年1 434篇(图 1),但 2022年的同比增速(53.70%)远低于 2019年的同比增速(86.04%)。结果提示,医院参与人工智能研究可能遇到了一系列挑战,发展可能进入瓶颈期。
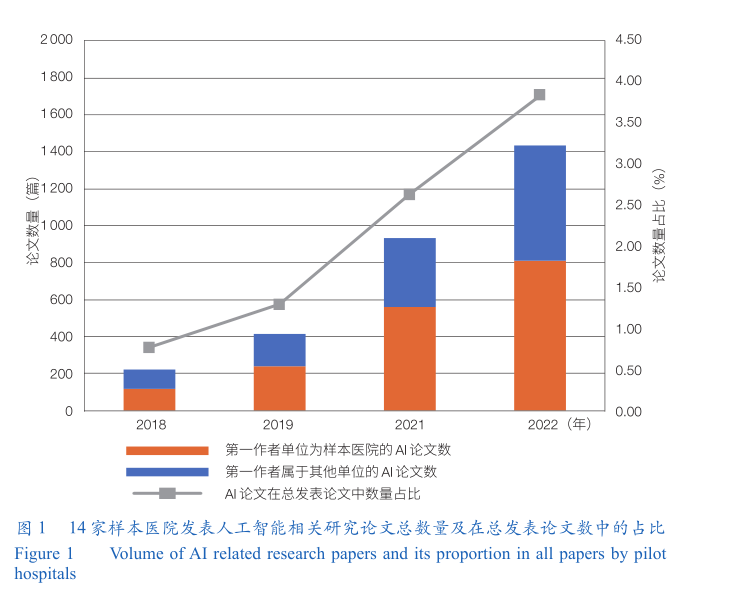
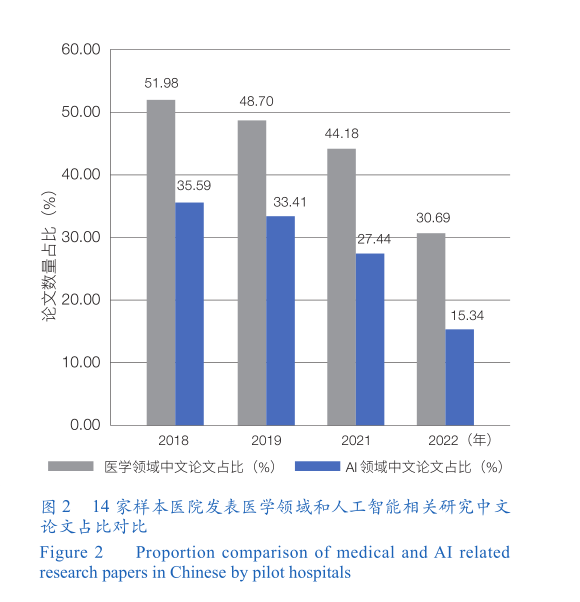
发表语言。以中文作为发表语言的论文数占比从 35.59%逐年下降至15.34%,且各年占比均低于全部领域论文中中文语言占比(图 2)。结果提示,医院的人工智能研究更倾向于发表在国际期刊上。
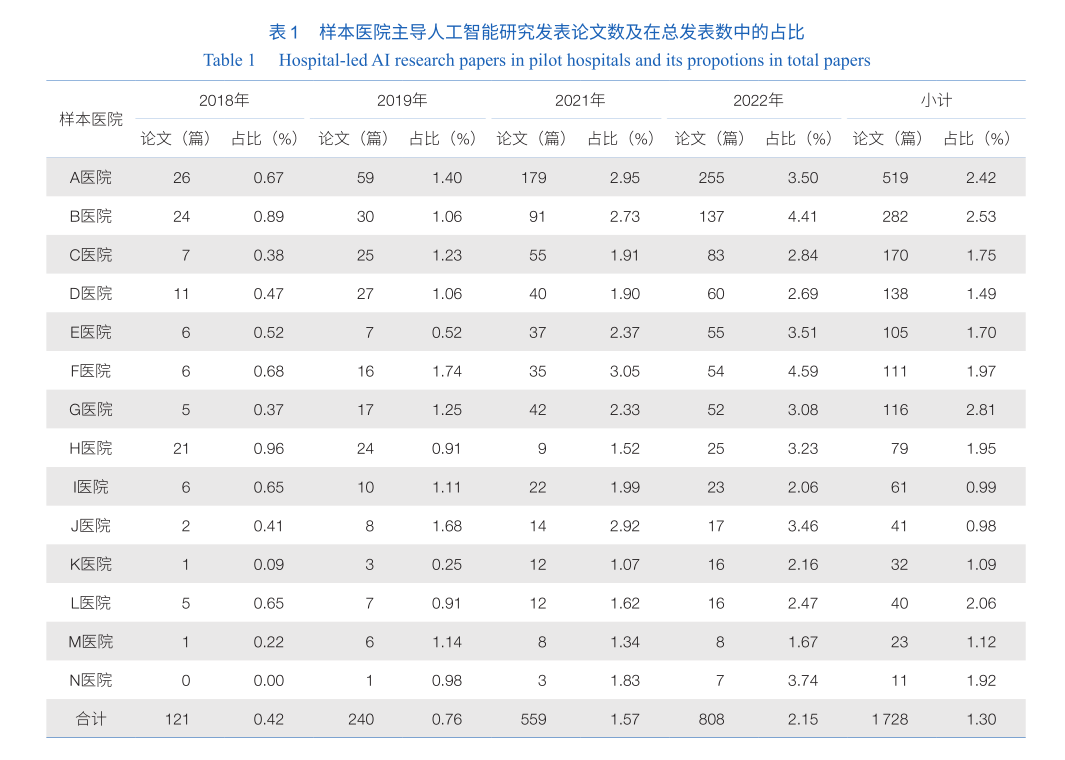
第一作者。本文以第一作者单位是样本医院的论文数量作为衡量医院主导人工智能研究的指标。样本医院主导发表了 1 728篇人工智能研究论文,占参与人工智能研究数的 57.56%。这说明,相当多的研究并非由医疗机构主导。主导人工智能研究最多是 A医院,2022年已达255篇,约占样本医院主导人工智能研究发表论文数的 1/3;同时,A医院的研究基数也较大(7 286篇)。主导人工智能研究数量排第 2位的B医院的研究基数也较大,情况与 A医院相似(表1)。结果提示,医院主导人工智能研究的发表数量与医院总体科研产出数量的相关度较高。
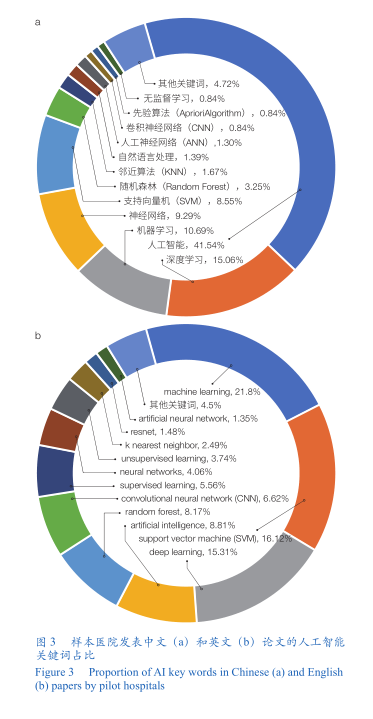
研究层次。虽然医院参与和主导的人工智能研究数量在提高,遗憾的是,医院主导人工智能研究质量仍可提高。约 55%的研究(67.29%的中文论文和 45.92%的英文论文)仅以“人工智能”或“深度学习”或“机器学习”作为关键词,这些论文大多尚停留展望、讨论人工智能可能应用于某领域的较浅的研究层次上。基于支持向量机(SVM)的前一代人工智能研究范式仍占样本医院主导人工智能研究的相当比例(图 3)。
人工智能相关专利
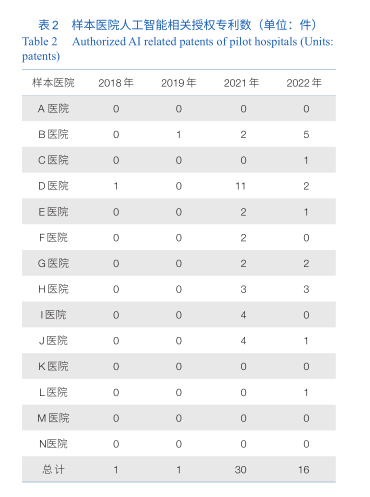
2021年以来,多家试点医院人工智能专利授权数实现了“零”的突破,总量也从 2018—2019年的2件提高到了2021—2022年的46件(表2)。其中,D医院2021年实现了 11件授权的高峰。然而,人工智能研究转化专利数量较少且不稳定,并未形成稳定的人工智能研究计划及产出。
医院主导深度人工智能应用研究的挑战分析
医院研究者主导人工智能研究的优势是更加接近临床需求,更加接近来自患者的多模态医疗健康数据,因而更有希望产出深度的、具有应用意义的人工智能研究成果。本研究发现,医院参与和主导的人工智能研究数量正在逐年增加,医院研究者对人工智能研究范式的热情越来越高涨,投入也越来越多。结合前文定量分析结果,本文通过深度访谈、专家咨询等方法,从学习应用、研究成本和研究的组织管理 3个层面,剖析医院主导深度人工智能应用研究存在的技术性挑战与困境。
学习曲线陡峭
系统学习深度神经网络范式。深度神经网络范式由一系列相互关联的技术路线和细节构成,知识容量较大。例如,常见的人工智能模型有卷积神经网络(CNN)、循环神经网络(RNN)、转换器(transformer)、生成式对抗网络(GAN)等。在最基础的 CNN模型中,研究者需要学习感知器、多层神经网络、卷积核、梯度下降、损失函数、正则化等一系列知识点。虽然医院的研究者大多接受过传统数理统计分析技术的训练,但很少有人接受过人工智能技术的系统训练。医院的研究者完成深度神经网络范式的系统性学习,往往只能利用工作之外的业余时间自学或参加相关培训班。
学习程序编写。①编程环境配置的挑战。人工智能的主流语言是 Python,但程序实现还需要依靠专门的中层框架。中层框架有多种选择,包括谷歌(Google)公司主导开发的 Tensorflow,脸书(Facebook)公司主导开发的 Pytorch,以及百度公司主导开源的飞桨(PaddlePaddle)等。每一种中层框架都处在快速的更迭之中,前一代的功能可能在后一代版本中被直接取消。对于初学者而言,需要花费很长的时间,才可能准确地在人工智能社区找到与本地环境相对应的解决方案。而一些使用者较少的中层框架,辅助学习资源则更少。②编程和排除编程错误的挑战。医院的研究者使用的数理统计软件,大多可以通过鼠标点选不同模块下的按钮实现,且这些软件常常配备详尽的使用说明。人工智能研究则需要研究者从“零”撰写程序,包括导入中层框架、加载必要基础模块等。研究者排除程序错误通常会花费比编写程序更多的时间。对初学者而言,遇到的绝大多数问题都需要向外部寻求解决方案。当辅助学习资源较少时,会对积极性造成致命的打击。③多模态数据挑战。在传统的数理统计研究中,进入统计模型的大多是结构化的、以数值为形式的数据。但在人工智能研究中,数据扩展至单一图像(如 X 线平片)、堆叠图像(如CT、核磁)、连续图像(如超声录像、内镜录像)、文本(如病历、诊断报告等)等多模态数据。研究者不得不学习将这些数据导出、输入到人工智能程序中需要的编程技能。
计算机相关英语语言能力。当前,高质量的人工智能入门书籍都以英文书写。虽然部分经典著作有中文译本,但由于翻译、出版存在周期,这些著作中援引的学习资源甚至中层框架都发生了变化。对于初学者而言,即使是一步步地照着做,可能也达不到预期的目的。相似的,多数高质量的人工智能技术讨论社区也是用英文作为主要语言。高水平医院的研究者的英文水平较高,但仍需迈过阅读和理解计算机领域研究的关口。这也从侧面印证了前文的发现,即越来越多的人工智能研究成果以英语发表在国际期刊上。
迭代计算产生时间和硬件成本
医院主导人工智能研究的迭代成本较高,而迭代成本主要可以分为时间成本和硬件成本 2 类,且这 2 类成本在一定程度上可以相互转化。
人工智能技术的迭代特性导致时间成本较高。机器学习算法通过自动迭代计算来获得神经网络模型的最优参数解,使用成本较低、普及度较高的中央处理器(CPU)计算需要耗费较长的时间。在深度学习的经典入门任务 MINIST数据集(手写数字数据集)中,图像大小为 28像素× 28像素,CPU可以在分钟级别的时间内完成多次迭代,获得最优解。但随着模型层数、迭代次数及图像大小的增加,时间成本将迅速提高。例如,在图像大小为 224像素× 224像素大小的ResNet-50网络模型(49 层)中,如果使用一颗高级别的 CPU迭代计算 90次,则需要约 700小时才能完成。在临床研究的实际问题中,使用成本较低的CPU计算人工智能的时间成本将超过研究者可接受的极限。一方面,常规的 X 线、CT和核磁的单幅图像横向或纵向分辨率都在 1 000像素以上;另一方面,具有实际应用意义的神经网络模型也在 10至数十层之间。
医院主导人工智能研究需投入相当高的硬件成本。相比 CPU,使用价格更高的图形处理器(GPU),可以大幅减少计算需要付出的时间成本。理论上,使用专业 GPU完成前文ResNet-50的计算任务比使用服务器级别的 CPU快近40倍。由于多数医学图像的辨析度较高、图层数较多,医院主导人工智能研究几乎难以避免地需要添置 GPU,有时还需要添置与之匹配的专门的计算平台。例如,美国麻省理工总医院(Massachusetts General Hospital)在基于本院的影像数据开发人工智能图像处理程序的任务中,专门引入了一台配备了 8部GPU(V100型号)、单价高达 12.9万美元的英伟达(NVIDIA)DGX平台。相似的,在美国梅奥诊所(Mayo Clinic)主导的一项基于核磁图像的 GAN研究中,也使用了DGX系列计算平台。目前,有实用价值的人工智能技术的参数量越来越大,对硬件的要求也越来越高。例如,当前热度极高的 ChatGPT模型的参数量高达1 750 亿,据受访专家估算,如采用单部 V100型号的GPU,需要计算约 355年。为加速计算,需要的投入成本也超乎想象。部分研究者坦言,人工智能实验室的组建需要首席研究员购置成本可观的设备,作为基础设施供研究组内的成员共享机器时间开展人工智能研究。对医院的人工智能技术潜在研究者而言,获取与研究设想相匹配的计算硬件资源是一项难度相当大的挑战。
将临床数据转化为高质量研究数据
将临床采集的数据转化为高质量的研究数据是人工智能研究的必要条件,但是尚需面对以下挑战。
临床生产的数据同质化水平不高。以图像为例,在质量同质化较低的医院中,生产图像的平台科室只需确保图像中包含有助于医师诊断疾病的部分即可,对局部出现在图像画幅上的位置、对比度等要求不高。在人工智能技术中,图像将被自动化地转化为由代表每一个像素的数值、向量或张量,然后投入人工智能模型。此时,图像的背景、亮度、色温,乃至研究兴趣区在画幅中的位置、大小、角度等因素都会产生噪声,干扰信号的提取。
储存、脱敏、提取、传输等数据处理相关问题。人工智能技术能够将更加接近采集端的数据直接纳入模型运算,信息损失更小。然而,靠近采集端的数据的体量远大于经过提取后的结构化数据;因此,调用、传输、储存往往都依赖医疗机构。然而,部分接受访谈的医院管理者提到,对数据进行提取、传输、备份等操作会产生可观的成本;因此,医疗机构往往不愿在挖掘数据中进行更多的投入。特别是,数据虽然储存在医院,但同时也属于患者个人;因此,还必须考虑到患者隐私、伦理、数据安全等方面。这些数据处理相关问题是将临床数据转化为高质量研究数据过程中必须解决的问题。
数据标注。研究指出,缺乏大规模高质量标注训练数据集是现阶段制约我国人工智能临床应用研究发展的关键因素。实际上,在传统的数理统计方法的研究中,研究者也需要花费相当多的工作量识别和标记图像关键点。这与人工智能研究中,人工标注因变量与标记图像关键点的工作并无本质不同。因此,固然标注数据是当前人工智能技术应用中需要关注的问题,却不是伴随人工智能技术而新出现的问题。
人工智能的可解释性较弱,使临床应用信心不足
人工智能的可解释性是研究者高度关注的议题,是人工智能研究的“皇冠”问题。可解释性难题来源于机器学习算法自动迭代参数的设计和深度神经网络中巨大的参数空间的结合。这使得人工智能被认为是复杂的“黑箱”模型。同时,人工智能技术天然地带有迭代性质,即从输入层不断接近和到达输出层的过程,也是从旧知识到新知识的过程。既往的求解结果可能是一个尚不能被科学知识及理性解释的结果,而这种不可解释性,会自然地继承到新生成的结果之中。
深度神经网络的研究结果往往由一系列对模型拟合能力的指标和预测能力构成,对熟稔传统数理统计的医院研究者而言,对人工智能结果进行解释和阐释的难度较大。在经典的数理统计中,研究者只需关注统计结果表格中的少数关键项,即可完成解释。例如,某两组数据的均值的 p 值小于或等于特定值(如 0.05),即意味着存在显著的统计学差异;若组间的差值存在临床意义,则进一步存在应用意义。由于几乎所有医院的研究者已几乎无条件地信任了统计学家和软件供应商提供的程序,基于传统统计学分析的方法,同行认可度更高。与之构成对比的情境是,当医院内熟悉人工智能方法的研究者较少时,研究者不仅需要解释人工智能生成的研究结果;多数时候,还需要对人工智能方法本身乃至技术细节进行解释。
一些旨在解决可解释性挑战的可视化算法的技术难度很高。医院研究者及团队很难依靠自身力量将这些技能内部化。研究者即使跨越了前文所述的学习关、成本关,获得了人工智能的研究结果,也会遇到结果解释的难题,难得到同行的充分认可。掌握团队资源、确定团队技术路线的团队带头人,面对人工智能可解释性较弱的特性,将很难下决心组织开展深层次研究与应用。
从政策推动到研究产出的管理建议
抓住研究范式转变机遇,引导投入研究资源
科学的发展存在着诸多的不确定性;在新的范式对旧的范式发出挑战时,更有可能产生新的突破性发现。当前,人工智能研究范式已经对传统的数理统计分析范式发起了挑战;而人工智能方法也以 SVM方法为核心,逐渐转向以深度神经网络为核心的新方法。虽然人工智能面临着可解释的挑战,但也应认识到,没有一种研究方法是完美的。只有面向人工智能研究投入资源才能逐步克服和优化解释问题。
国家层面,抓住研究范式转换的历史机遇,面向人工智能发展过程中的难点和痛点,在新旧动能转换的过程中进一步加大支持力度。例如,可以通过设置综合医院的国家人工智能医学研究中心,设置互联网医院、智慧医院等样板医院,以及面向人民生命健康的人工智能相关“揭榜挂帅”攻关课题等方式,培育公立医院在发展人工智能中的良好的竞争文化,同向发力,实现“弯道超车”的政策推动目标。
医院层面,优化人工智能研究领域的资源投入。通过开设人工智能课堂、组建院级人工智能计算共享平台,设置专门孵育项目等方式,加大对支持力度,鼓励以人工智能方法为核心或将人工智能方法与传统统计方法相结合的研究。通过营造良好的人工智能研究文化,审慎组织,面向人工智能的技术性挑战,跨越人工智能技术性障碍。
面向人工智能技术,布局多模态数据资源
推动人工智能研究走向深入,医院还应主动布局多模态数据资源结构。医院可采取更加开放的态度,允许研究项目获得小规模的患者数据作为数据集。创新条件较好的医院可搭建人工智能数据平台,允许经研究团队标注的小规模样本集对院内研究者开放,供研究者熟悉和优化改进数据集。对一些基于院内公开的小样本集已经取得成果的项目,设置快速扩容数据量及伦理等相关工作审批流程,加速孵化人工智能研究。
医院内的研究团队可根据研究资源主动参与多模态数据布局。资源较丰富的医院研究者团队可尝试使用无监督学习聚类等机器学习算法,从多个维度对数据进行描述与归类,提前对数据进行小规模尝试性标记,建立研究者及研究团队专属的多模态数据的小样本库。掌握研究资源不丰富的研究者可在使用传统统计方法进行病例研究的同时,留意收集该病例的多模态数据,逐步尝试纳入多模态数据并应用人工智能方法拓展研究。
培养人工智能协调员,推动人工智能研究走向深入
医院可采取培养人工智能协调员的方法,进一步推动人工智能临床应用研究走向深入。研究指出,医院应采取多学科合作模式发展人工智能的路径。事实上,部分高质量发展试点医院也已启动了高校、科研院所和医疗机构之间的合作。但无论是研究建议还是实践,均未聚焦担任团队间“桥梁”的院内工作角色。美国医院协会的报告指出,人工智能的发展可能促使医院设置包括人工智能工程师、首席人工智能官等角色的院内工作人员。受访专家指出,如果医院研究团队内没有承担人工智能协调员角色的研究者,医院团队与外部技术团队之间的沟通与协作会经常性地遇到障碍。医院应着力培养了解人工智能的基础框架、知识点,具备初步的人工智能研究能力的人工智能协调员。这些协调员可以在医院研究团队和外部人工智能技术团队之间架起沟通“桥梁”,更好地沟通研究需求与研究方法,从而不断推动人工智能研究走向深入。
本研究聚焦医院主导人工智能研究,总结和分析了医院研究者在尝试学习和应用人工智能技术时需要跨越的技术性难题,可为医疗机构和管理部门制定政策和实施管理提供参考。医院主导人工智能研究的技术性难题在于,人工智能技术学习曲线陡峭、迭代成本高、高质量多模态研究数据难得和人工智能可解释较弱。考虑到人工智能技术有望加速信息提取与运算过程,扩展纳入研究的数据模态,产出有深度的、具有临床应用意义的研究成果,医疗机构应当主动响应政策推动,调动内部资源,主导人工智能技术内部化。未来,可通过培养人工智能协调员,培育人工智能高端人才,面向人工智能技术布局多模态数据资源,促进研究产出。
(作者:庄昱,北京大学哲学系 北京大学第三医院;周程,北京大学哲学系 北京大学医学人文学院;《中国科学院院刊》供稿)





